On December 5, 2023, Web3 development platform thirdweb reported security vulnerabilities in their prebuilt smart contracts. This flaw impacted all ERC20, ERC721, and ERC1155 tokens deployed using these contracts. In the following days, tokens deployed with the vulnerable contracts were progressively exploited in attacks.
Thirdparty libraries play a critical role in software security, yet their importance is frequently underestimated. Modern software development relies heavily on reusing code from open source libraries. In smart contract programming, thirdparty libraries like OpenZeppelin are popular to incorporate security best practices and save time. But dependencies can still pose unforeseen dangers. The thirdweb hack is a typical example.
The root cause is that the forwarders (ERC-2771) were not designed to work with multicall.
ERC-2771: This EIP defines a contract-level protocol for Recipient contracts to accept meta-transactions through trusted Forwarder contracts. No protocol changes are made. Recipient contracts are sent the effective msg.sender (referred to as _msgSender()) and msg.data (referred to as _msgData()) by appending additional calldata.
In practice, OpenZeppelin's ERC2771Context is widely used. The last 20 bytes of calldata from trusted forwarder is treated as _msgSender(). For common library users, it seems that they only need to replace all uses of msg.sender with _msgSender().
function _msgSender() internal view virtual override returns (address) {
uint256 calldataLength = msg.data.length;
uint256 contextSuffixLength = _contextSuffixLength();
if (isTrustedForwarder(msg.sender) && calldataLength >= contextSuffixLength) {
return address(bytes20(msg.data[calldataLength - contextSuffixLength:]));
} else {
return super._msgSender();
}
}
function _msgData() internal view virtual override returns (bytes calldata) {
uint256 calldataLength = msg.data.length;
uint256 contextSuffixLength = _contextSuffixLength();
if (isTrustedForwarder(msg.sender) && calldataLength >= contextSuffixLength) {
return msg.data[:calldataLength - contextSuffixLength];
} else {
return super._msgData();
}
}
User can utilize multicall to integrate multiple calls into one single call. The calldatas of multiple calls extracted from the calldata of single call. In practice, OpenZeppelin's MulticallUpgradeable is widely used. (The bug is fixed now)
function multicall(bytes[] calldata data) external virtual returns (bytes[] memory results) {
results = new bytes[](data.length);
for (uint256 i = 0; i < data.length; i++) {
results[i] = _functionDelegateCall(address(this), data[i]);
}
return results;
}
The issue arises due to inconsistencies in how calldata is packed and unpacked between these two components (ERC-2771 and Multicall):
-
As per ERC2771, the trusted forwarder should pack the message data and sender information together. The contract then uses _msgData() and _msgSender() to unpack the message data and sender information, respectively.
-
However, the multicall function is not compatible with how ERC2771 packs data. In the correct implementation, multicall should use _msgSender() to unpack the sender information and append it to each message's calldata, so it can be unpacked properly in subsequent calls. But this step is missed.
-
Meanwhile, the contract following ERC2771 will try to unpack message data and sender information using _msgData() and _msgSender(). However, without the sender information appended to calldata, the sender information is unpacked as the last 20 bytes of _msgData(), which can be controlled by the attacker.
This allows an attacker to construct manipulated calldata that executes malicious logic with an arbitrary sender information, violating the expectations set by the specifications.
Many tokens that use both of these libraries are vulnerable to similar attack methods. The attacker utilize the bug to impersonates the swap pool to burn its token, causing the price of token up. Then do a swap and draining the entire liquidity.
Let's take one instance of an attack transaction as an example.
https://phalcon.blocksec.com/explorer/tx/eth/0xecdd111a60debfadc6533de30fb7f55dc5ceed01dfadd30e4a7ebdb416d2f6b6
- Swap 5
$WETH for 3,455,399,346 $TIME.
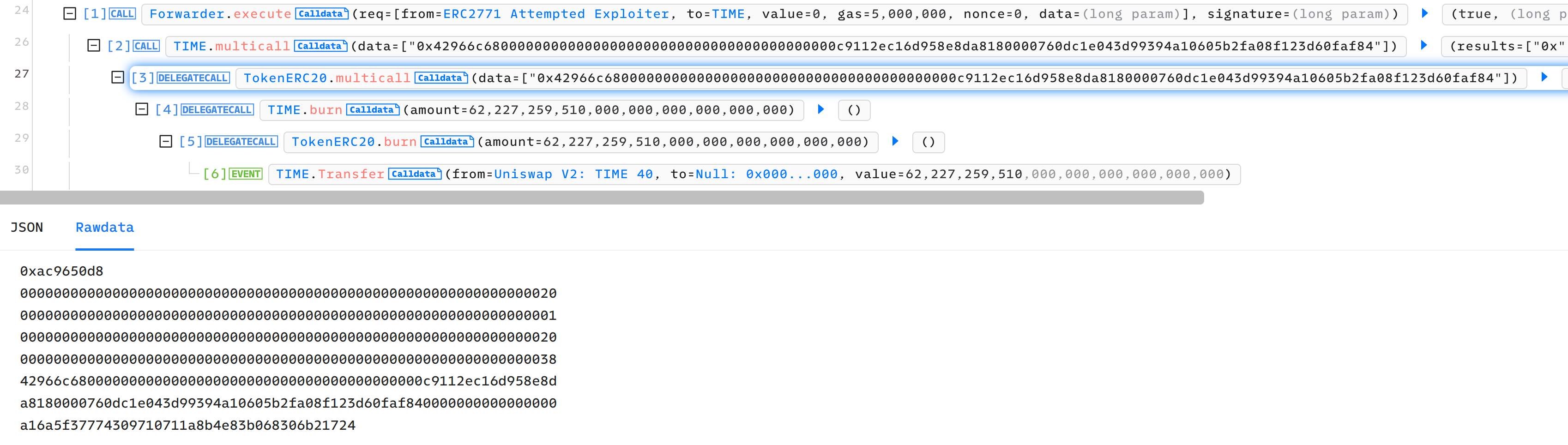
- Invoke trusted forwarder with carefully crafted data, after being parsed by multicall, the burn function is called with Uniswap Pool as the
_msgSender(). The $TIME balance of pool is decreased.
- Sync the pool, the price of
$TIME is lifted.
- Swap 3,455,399,346
$TIME for 94 $WETH.
The step 2 is the key of attack. Attacker invoke Forwarder.execute to forward data:

However, it is parsed as bytes[] of length 1, then used as data to call the contract.

In the DeFi space, it is crucial to also pay attention to the security of third-party libraries. Unfortunately, these libraries can sometimes interact with each other in unexpected and covert ways, posing a threat to the security of the contract. This highlights the importance of thorough auditing and monitoring to mitigate any potential vulnerabilities that may arise from such interactions.