Basic
这里都是通用的性能优化法则。一些特殊情况,一些特定场景的办法都不会介绍到。
索引——空间换时间
索引的原理是拿额外的存储空间换取查询时间,增加了写入数据的开销,但使读取数据的时间复杂度一般从 O(n) 降低到 O(logn) 甚至 O(1)。
如果我们想在程序中存储一系列数据,除了基本的数组和 Vector,还可以使用下面这些带索引的数据结构:
- Hash Table 的 增删改查 算法复杂度 是 O(1),实际上就是用 Hash 值作为索引。
- 红黑树/AVL 树/B Tree:也可以当作索引。由于他的树形结构,让我们不需要用遍历的方式查找内容。
- Trie:这种结构能非常方便的做前缀查找或词频统计
- 倒排索引:搜索引擎使用的技术,帮助我们快速在全文搜索关键词。
数据库的索引。
缓存和预取 (Cache & Buffer)
压缩——时间换空间
在网络传输中用到压缩算法尤其多
- 我们经常看到 HTTP 的请求头里头有
Accept-Encoding: Gzip/deflate,就是用无损压缩算法对数据进行了压缩 - 我们网上看到的图片和视频可能是有损压缩后的结果,比如 jpg
- JVM 的对象指针压缩,JVM 在 32G 以下的堆内存情况下默认开启“UseCompressedOops”,用 4 个 byte 就可以表示一个对象的指针,这也是 JVM 尽量不要把堆内存设置到 32G 以上的原因
- 布隆过滤器其实也可以算?
削峰填谷
记得在字节的时候有人专门研究这玩意儿。
- 代码和数据等资源的 延时加载、分批加载、后台异步加载、或按需懒加载 等等。
- 我们在使用库函数对文件进行写入的时候,可能会先写到 buffer 里面。
并行和异步
这里其实有很多可说的,只是我才疏学浅
- 对于计算密集型的程序,尽量以 CPU 的个数进行多进程处理,多线程(Python 除外,他有 GIL)也差不多。
- 对于 IO 密集的程序,可以使用协程,多线程。
- 使用线程池,减少内核切换的开销。
- 使用无锁结构,我只是听说过这个东西,并不太清楚具体是什么。
Linux 性能分析
大佬 Brendan’ 介绍了很多在 Linux 上进行性能分析的方法。他绘制了一张图,分析程序各个部分的情况。比较值得注意的是 perf。
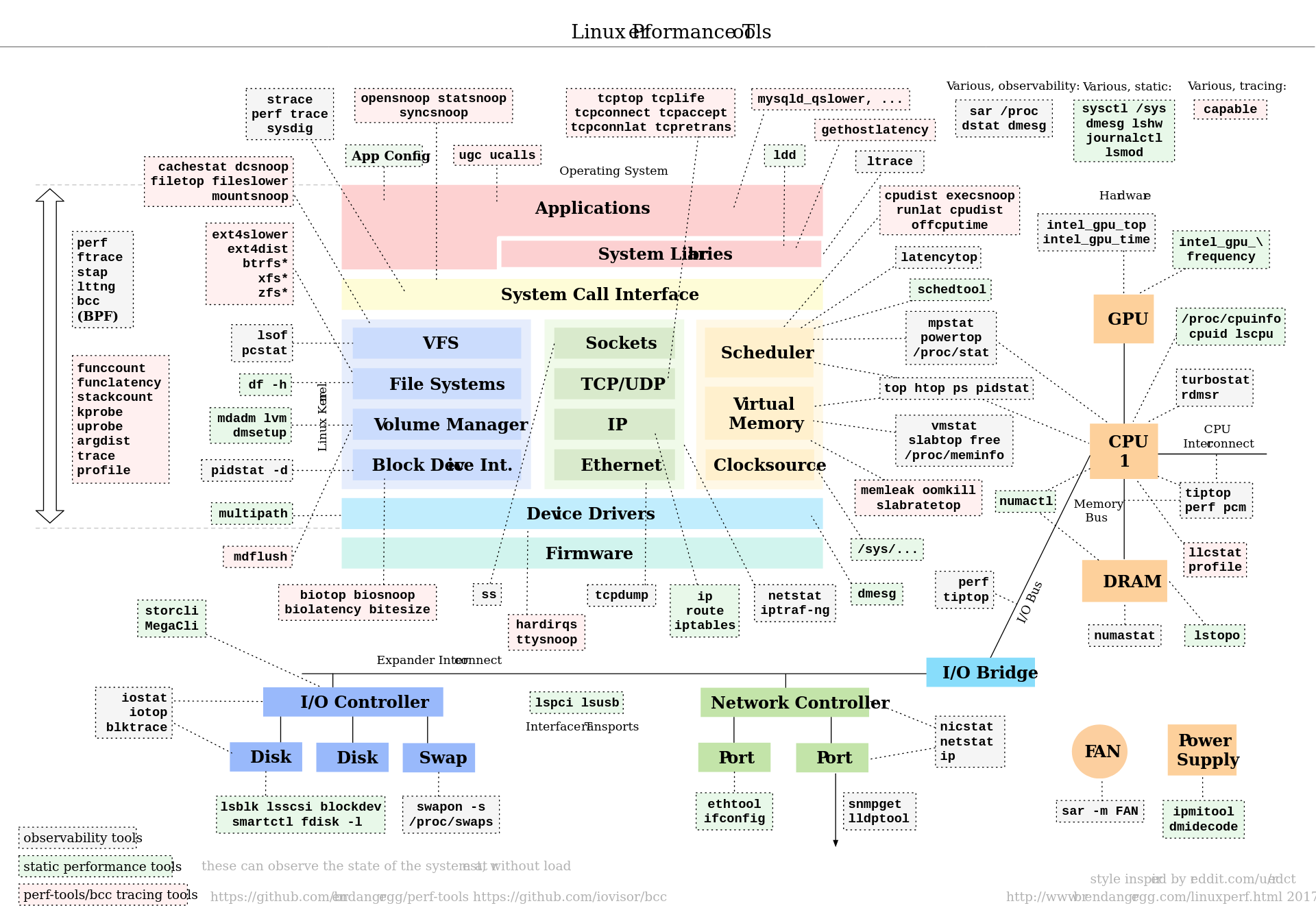
基础分析工具
这些工具能让我们对程序的资源占用情况有基本认识。
底层工具
| 工具名称 | 作用 |
|---|---|
| uptime | uptime 命令显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的 1 分钟、5 分钟和 15 分钟内的平均负载。 |
| top | 查看 CPU 占用情况 |
| vmstat | 查看虚拟内存使用情况 |
| iostat | 查看 IO 使用情况 |
| mpstat | 查看每个 CPU 的使用情况,适用多核 |
| free | 内存使用情况 |
中间层工具
| 工具名称 | 作用 |
|---|---|
| strace | 查看系统调用使用情况,但是非常消耗性能 |
| tcpdump | 抓包 |
| netstat | 网络状态 |
| pidstat | 针对某个进程的 CPU 监控,可取代 top |
| swapon | 查看 swap 分区的使用情况 |
| sar | system activity reporter, 可以监控很多情况 |
| collectl |
这都是最基本的工具。。